Contoh Kasus Analisis Diskriminan
Suatu penelitian ingin mengetahui karakteristik sosial demografi yang dapat membedakan antar kelompok anak berdasarkan level kenakalannya di PSMP Handayani dan BRSMP Harapan dan ingin mengetahui karakteristik sosial dan demografi anak nakal tersebut berdasarkan jenis kenakalan yang dilakukan oleh anak yang dibina di PSMP Handayani dan BRSMP Harapan. Maka analisis yang digunakan dalam penelitian tersebut adalah analisis diskriminan.Variabel independen yang digunakan:
X1: Kenakalan
X2: Nilai tes IQ
X3: Kecerdasan Emosional
X4: Perilaku sebelum masuk panti
X5: Keharmonisan keluarga
X6: Pendidikan Anak
X7: Rata-rata Lama Bermain
X8: Umur Anak
X9: Jumlah Anggota rumah tangga
X10: Jumlah Bersaudara Kandung
X11: Pendidikan Pengasuh
Variabel dependen: Y: Tingkat Kenakalan : (Nakal menengah keatas dan Nakal Ringan)
Berikut Langkah-langkah dalam analisis diskriminan:
- Masukkan data yang akan diolah. seperti pada gambar di bawah.

- Pada menu Analyze, pilih submenu Classsify, lalu pilih Discriminant. Pada kotak dialog Discriminant Analysis, pindahkan Nakal_Rev2 ke dalam Grouping Variable, lalu klik Define Range.

- Lalu pada kotak kecil, bagian minimum diisi dengan kode terkecil dan maximum diisi dengan kode terbesar dari variabel respon, pada contoh kasus disini,masukkan angka “1” untuk minimum dan “2” untuk maximum. Kemudian klik Continue.

- Kembali ke kotak dialog Discriminant Analysis, lalu pada Independents diisi dengan variabel penjelas. Metode yang sering dipaparkan pada literatur-literatur adalah metode bertatar (stepwise), maka kali ini hanya akan diberi contoh penggunaan metode ini. Pada contoh kasus di sini, variabel independents adalah variabel yang tersisa tadi. Kemudian pindahkan variable yang tersisa ke dalam Independents.lalu, pilih dan klik Statistics.

- Pada kotak kecil, centangkan kotak means, univariate ANOVA’s, Box’s M, serta Unstandardized. Lalu, Continue.

- Kembali ke kotak dialog Discriminant Analysis, lalu pada Classification, lalu diberi tanda cek di All group equal, Casewise result, Summary table, dan Within-groups. Lalu, klik Continue.

Interpretasi hasil analisis diskriminan
Uji Asumsi Analisis diskriminan
Uji Kesamaan matriks ragam-peragam antar kelompok
Pada kasus ini, kita menguji asumsi kesamaan matrik ragam-peragam antara kelompok nakal menengah ke atas dan nakal ringan digunakan statistic uji Box’s M.
Dengan tingkat kepercayaan 95%, kelompok-1 dan kelompok-2 memiliki matriks ragam-peragam yang sama dilihat nilai sig 0.46 yang lebih besar dari 0.05(alpha). Asumsi semua kelompok memiliki matrik ragam-peragam yang sama terpenuhi. Selain itu, kesimpulan dapat diambil dengan melihat nilai log determinan dari tiap-tiap kelompok pada tabel log determinants. Nilai log determinan kelompok menengah ke atas = 13.103 dan kelompok ringan = 12.132. Hasil keduanya relative sama, yang mengindikasikan ragam-peragam untuk tiap kelompok sama.
Perbedaan rata-rata antar kelompok
Untuk uji perbedaan rata-rata antar kelompok menggunakan uji wilks lambda.
Selain itu, juga dapat dilihat dari hasil tabel Test of Equality of Group Means mengenai perbedaan signifikan antar kelompok pada setiap peubah bebas.
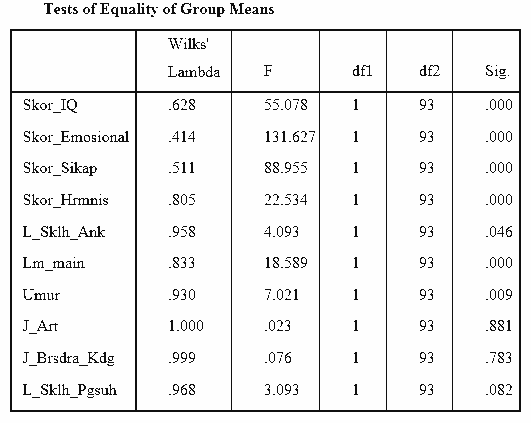
- Karakteristik IQ, Kecerdasan Emosional, Sikap, Keharmonisan Keluarga, Lama SekolahAnak, Lama waktu bermain, dan Umur memiliki P-value < 0,05 berarti bahwa kategori anak nakal ringan berbeda signifikan dengan anak nakal menengah ke atas. Terdapat 7 peubah yang signifikan berbeda antar kelompok.
- Dalam pengolahan SPSS nilai jumlah peubah p, dari hasil output ini terdapat 70% dari p yang berbeda signifikan. Karena ≥ 50% p, maka analisis diskriminan dapat dilakukan.
- Asumsi perbedaan rata-rata antar kelompok telah terpenuhi karena lebih dari 50 persen dari total peubah yang dianalisis telah signifikan berbeda antar kelompok.
- Tiga peubah yang tidak signifikan yaitu jumlah anggota rumah tangga, jumlah saudara kandung, dan lama sekolah pengasuh. Ketiga peubah yang tidak lolos akan dikeluarkan dari daftar peubah yang akan disertakan pada analisis diskriminan.
Analisis Hasil Analisis Diskriminan
Stepwise statistics

Summary of Canonical Discriminant
Nilai akar ciri (eigen value) menunjukkan ada atau tidaknya multikolinearitas antar peubah bebas. Multikolinearitas akan terjadi bila nilai akar ciri (eigen value) mendekati 0 (nol). Berdasarkan hasil pengolahan data didapatkan nilai akar ciri yang menjauhi nol, yaitu sebesar 2,709. Keadaan ini dapat diartikan bahwa fungsi diskriminan yang diperoleh cukup baik karena tidak terjadi multikolinearitas di antara sesama peubah bebasnya.
Pada tabel Eigen Value terdapat nilai canonical correlation. Canonical correlation digunakan untuk mengukur derajat hubunggan antara besarnya variabilitas yang mampu diterangkan oleh variabel independen terhadap variabel dependen. Dari tabel di atas, diperoleh nilai canonical correlation sebesar 0,855, bila dikuadratkan menjadi (0,855x0,855)=0,7310; artinya 73,10% varians dari variabel dependen dapat dijelaskan dari model diskriminan yang terbentuk
canonical discriminant function coefficients

Y = -10,467 + 0,072IQ + 0,168Emosi + 0,076Perilaku + 0,047Harmonis.
Function at Group Centroid

Group Centroid merupakan rata-rata nilai diskriminan dari tiap-tiap observasi di dalam masing-masing kelompok. Group Centroid untuk kelompok nakal menengah ke atas adalah sebesar -1,161, sedangkan untuk kelompok nakal ringan adalah sebesar 2,285. Ini berarti bahwa secara rata - rata skor diskriminan kedua kelompok berbeda cukup besar. Sehingga fungsi diskriminan yang diperoleh dapat membedakan secara baik kelompok yang ada.
Classification results

Untuk materi tentang analisis diskriminan silahkan di klik Materi analisis diskriminan
.





kak, apakah boleh jika saya ingin meminta data ini?
ReplyDeleteNice explanation
ReplyDeleteselamat sore. maaf gan mau nanya kalo menggunakan 3 kelompok data gimana cara menginterpretasikan nilai sig nya gan?
ReplyDeleteselamat sore. maaf gan mau nanya kalo menggunakan 3 kelompok data gimana cara menginterpretasikan nilai sig nya gan?
ReplyDelete